
In questo breve articolo si cerca di rendere evidente l’ipotesi che la produttività del lavoro, sia nella dimensione temporale che in quella spaziale, è aumentata anziché diminuita, come sostengono gli economisti mainstream.
Secondo questi ultimi i salari ristagnano o diminuiscono perché non ci sarebbero incrementi di produttività. In base a questa impostazione, solo se aumenta la produttività del lavoro si verifica un aumento dei salari.
Questo assunto contraddice la realtà empiricamente osservabile. Tanto per fare un esempio: un operaio della FIAT di Mirafiori, negli anni settanta, produceva 10 macchine in un anno, mentre con gli attuali ritmi di produzione, se si lavora a tempo pieno e grazie soprattutto alle innovazioni tecnologiche, un operaio di Melfi è in grado di produrne 65 all’anno.
L’analisi dei dati elaborati rende valida l’ipotesi proposta.
Nell’analisi che qui propongo le dimensioni temporali e spaziali vengono rappresentate mediante un modello di regressione lineare a due variabili. L’approccio che viene utilizzato è semplice, ma non banale: si cerca di cogliere un nesso importante con un linguaggio matematico fruibile.
I dati mostrano che la produttività del lavoro è più alta della sua remunerazione, quindi il modo di ragionare secondo il quale non ci sarebbero incrementi salariali per via della bassa produttività è fuorviante, e a mio avviso, poggia su un terreno ideologico.
1. Commento ai dati
I dati utilizzati nel modello sono stati estratti dall’archivio AMECO. Essi riguardano 14 paesi, 11 dell’UE e 3 dell’area OCSE: USA, Canada e Giappone. Per questi ultimi paesi è stato necessario recuperare le serie storiche dei tassi di cambio, in modo da renderli omogenei con quelli dei paesi europei espressi in euro.
Il salario orario non è direttamente disponibile nel database dell’UE, quindi è stato calcolato utilizzando la percentuale della ricchezza che è confluita nei salari, nel range temporale preso come riferimento (1984-2010), sul totale del GDP per persona impiegata. Il valore ottenuto è stato poi diviso per il numero di ore di lavoro erogate in media in ciascun paese.
Nella costruzione del modello sono stati lasciati fuori quei paesi dell’UE per i quali i dati non erano disponibili, nell’arco di tempo considerato. Purtroppo, l’esclusione ha riguardato anche la Germania, poiché nel database AMECO, a partire dalla data dell’unificazione, le serie storiche delle due variabili prese in considerazione non sono presenti. Tenendo conto del peso politico ed economico della Germania nell’ambito dei paesi OCSE, i dati si sarebbero potuti ottenere per altra via, ma penso che questa omissione non infici la sostanza della dimostrazione: il campione oggetto di studio rimane a mio parere significativamente rappresentativo. Sul piano temporale è interessante far notare che:
a) negli anni 60-70 il differenziale fra produttività per ora lavorata e salario orario era negativo, quindi conferma la tesi che in quel periodo il salario era considerato una variabile indipendente;
b) a partire dagli anni 80, invece, il trend si inverte e gli aumenti di produttività superano sistematicamente le retribuzioni orarie;
c) l’evidenza empirica di questo differenziale dimostra l’inversione di marcia delle politiche economiche internazionali nei primi anni ottanta.
2. Analisi del modello
Nella stesura del modello è stato utilizzato il metodo data set Panel. Esso consiste nel ripetere le osservazioni in punti distinti nel tempo. Nel nostro caso le unità (punti) prese in considerazione sono un gruppo dei paesi dell’area OCSE, in termini formali: Yit. Con i che va da 1 a 14 mentre t va dal 1984 al 2010, le variabili esplicative sono 2, k=2. Quello che caratterizza una struttura Panel non è la dimensione temporale ma il fatto che la variabilità dei dati avvenga in più dimensioni.
Partendo dall’analisi grafica delle due serie si può affrmare che entrambe non sono stazionarie. Infatti, è evidente che i trend sono crescenti.
Sulle ascisse sono riportate le dimensioni spaziali e temporali, mentre sulle ordinate sono espressi i valori orari delle due variabili.
Se mettiamo a confronto i due grafici, ci si rende immediatamente conto che i valori del GDPWH superano costantemente quelli dell’ HWAGE.
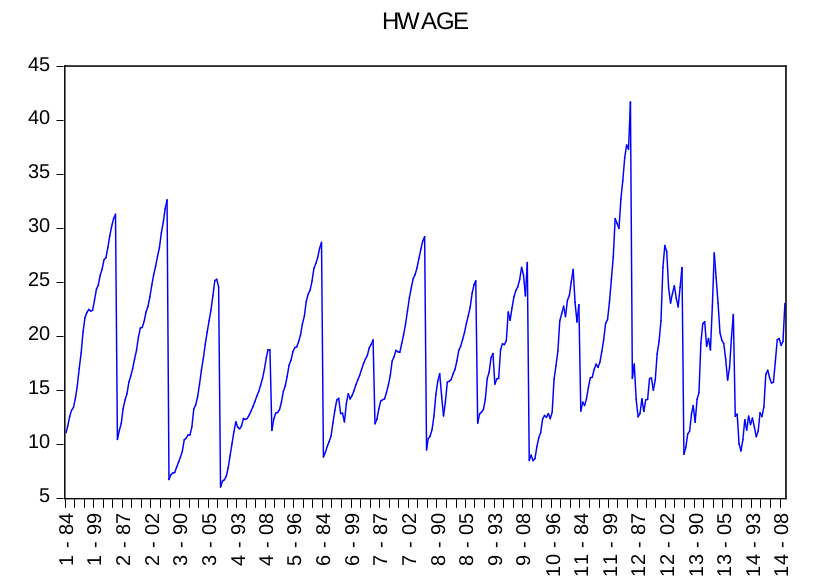
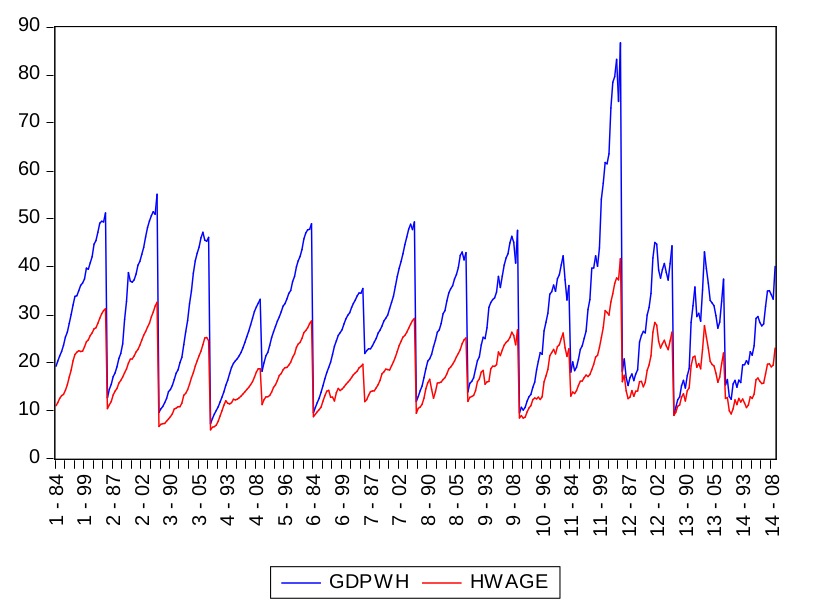
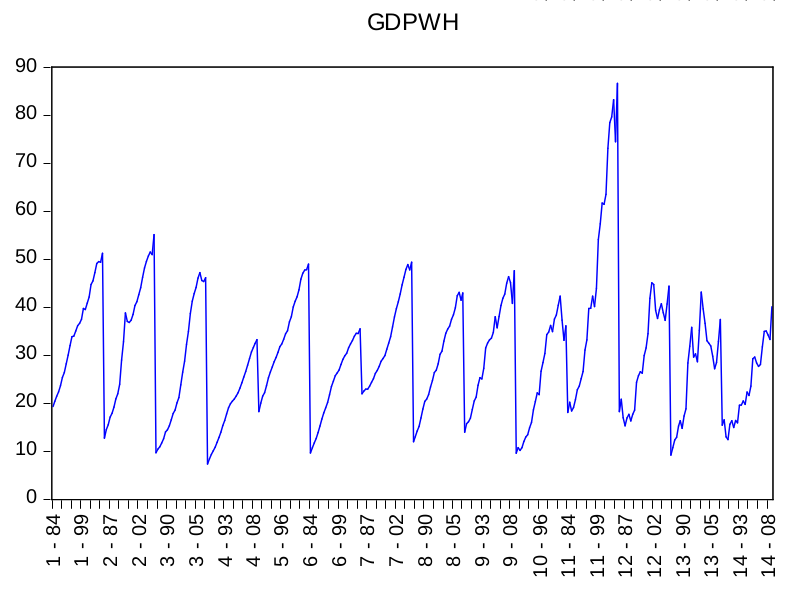
I risultati sono stati ottenuti con il programma econometrico EViews.
L’equazione è stata stimata con il metodo Panel EGLS (Cross-section weights).
Il campione è costituito da 378 osservazioni. Il modello è costituito da un equazione lineare dove HWAGE (salario orario) rappresenta la variabile dipendente, mentre GDWH (produttività per ora lavorata) rappresenta la variabile indipendente.
L’equazione stimata ottenuta con il programma è la seguente:
HWAGE = C(1) + C(2)*GDPWH + [CX=F]
Substituted Coefficients:
=========================
HWAGE = 3.95388434231 + 0.467533833868*GDPWH + [CX=F]
Il parametro b = 0.467533833868 indica una correlazione positiva tra le due variabili, cioè l’aumento di GDPH determina un aumento del salario orario. Tuttavia, l’incremento della variabile dipendente è meno che proporzionale. Infatti, se in essa confluiscono solo il 46% degli incrementi produttivi, allora che fine fa la restante parte? Con molta probabilità questi incrementi vengono assorbiti dai profitti che, se non vengono utilizzati per i nuovi investimenti, vanno ad ingrossare il canale della rendita finanziaria. Gli incrementi di produttività, se gli investimenti ristagnano o addirittura diminuiscono, contribuiscono a ridurre la domanda di lavoro socialmente necessaria alla produzione dei beni e servizi. Si crea una situazione paradossale dove ad una maggiore capacità produttiva corrisponde un aumento dell’impoverimento sociale.
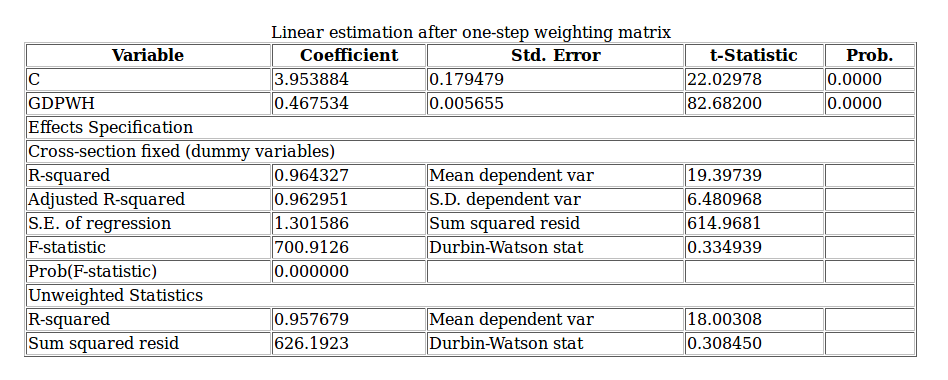
L’R squared e l’ Adjusted R squared sono entrambi prossimi a 1 , quindi significa che i repressori predicono bene il valore della variabile dipendente in campione
| GDPWH | HWAGE | |
| Mean | 30.04958 | 18.00308 |
| Median | 29.26681 | 17.02719 |
| Maximum | 86.70552 | 41.71218 |
| Minimum | 7.330000 | 6.031447 |
| Std. Dev. | 13.09894 | 6.264741 |
| Skewness | 0.900043 | 0.594403 |
| Kurtosis | 4.763360 | 3.130758 |
| Jarque-Bera | 100.0085 | 22.52813 |
| Probability | 0.000000 | 0.000013 |
| Sum | 11358.74 | 6805.164 |
| Sum Sq. Dev. | 64686.53 | 14796.11 |
| Observations | 378 | 378 |
Test di normalità di Jarque –Bera.
Consideriamo l’ipotesi nulla che la distribuzione della popolazione sia normale, il test si basa sulla vicinanza dell’asimmetria campionaria a 0 e della curtosi campionaria a 3 . La statistic test è:
B = n [ ( asimmetria )^2 / 6 + ( Curtosi – 3 )^2 / 24 ]
Se si sostituiscono i valori della variabile indipendente avremo :
B = 378 [ ( 0.900043 )^2 / 6 + (( 4.763360 – 3 )^2 / 24 ] = 100,0080
Il valore 378 è compreso fra 300 e 400, mentre il livello di significatività al 10 e al 5 per cento sono rispettivamente 3,72 e 4,66, pertanto si rifiuta l’ipotesi che la popolazione sia normale .
- © Riproduzione possibile DIETRO ESPLICITO CONSENSO della REDAZIONE di CONTROPIANO
Ultima modifica: stampa



